RenderNet: A deep convolutional network for
differentiable rendering from 3D shapes
Thu Nguyen-Phuoc, Chuan Li, Stephen Balaban, Yong-Liang Yang
Neural Information Processing Systems NeurIPS 2018
Abstract
Traditional computer graphics rendering pipeline is designed for procedurally generating 2D quality images from 3D shapes with high performance. The non-differentiability due to discrete operations such as visibility computation makes it hard to explicitly correlate rendering parameters and the resulting image, posing a significant challenge for inverse rendering tasks. Recent work on differentiable rendering achieves differentiability either by designing surrogate gradients for non-differentiable operations or via an approximate but differentiable renderer. These methods, however, are still limited when it comes to handling occlusion, and restricted to particular rendering effects. We present RenderNet, a differentiable rendering convolutional network with a novel projection unit that can render 2D images from 3D shapes. Spatial occlusion and shading calculation are automatically encoded in the network. Our experiments show that RenderNet can successfully learn to implement different shaders, and can be used in inverse rendering tasks to estimate shape, pose, lighting and texture from a single image.
Method overview
RenderNet receives a voxel grid as input, and applies a rigid-body transformation to convert from the world coordinate system to the camera coordinate system. The tranformed input, after being trilinearly sampled, is then fed to a CNN with a projection unit to produce a rendered 2D image. RenderNet consists of 3D convolutions, a projection unit that computes visibility of objects in the scene and projects them onto 2D feature maps, followed by 2D convolutions to compute shading. We train RenderNet using a pixel-space loss between the target image and the output.
The projection unit consists of a reshaping layer, and a multilayer perceptron (MLP). For the reshaping step of the unit, we collapse the depth dimension with the feature maps to map the incoming 4D tensor to a 3D squeezed tensor V' with dimension W×H×(D·C). This is immediately followed by an MLP, which is capable of learning more complex structure within the local receptive field than a conventional linear filter. We apply the MLP on each (D·C) vector, which we implement using a 1×1 convolution in this project.

Results

RenderNet can learn to create a variety of shaders
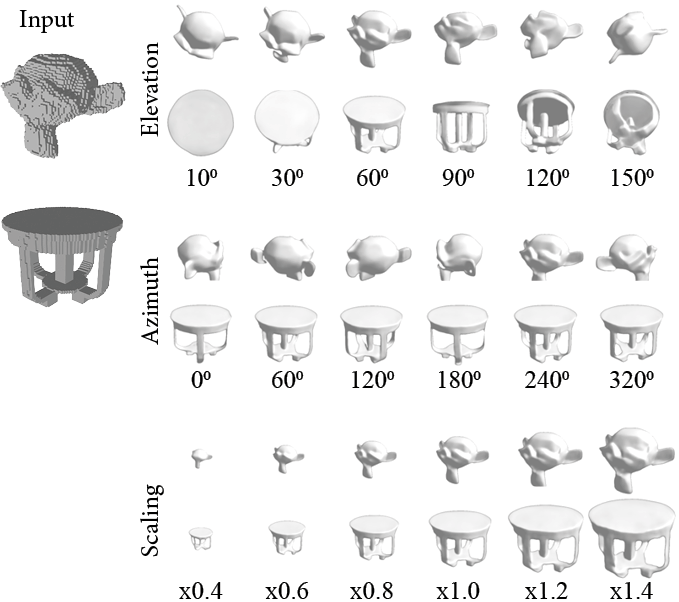
RenderNet was trained on the chair category, but can generalise well to other categories from different views.

Comparing RenderNet with an encoder-decoder network, which fails to generate sharp images and generalise to different types of geometry.

Image-based reconstruction and novel view synthesis
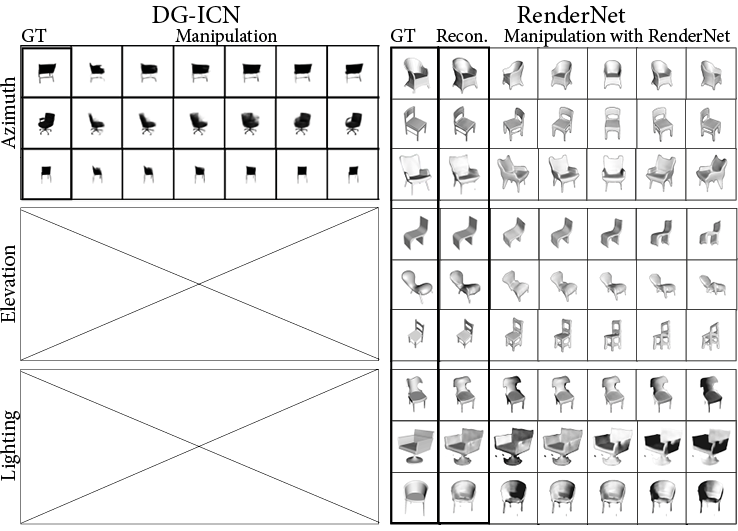
Image-based reconstruction and novel view synthesis